Support Vector machine , the easiest way

introduction
While learning machine learning we stumble upon many regression and classification algorithms. Support vector machine is one of them. It is one of the popular machine learning algorithm. Although it can be used both as classifier and regressor. However it is primarily used for classification tasks.
Description:
Let’s say you have a data set that have n features and one label which is a binary categorical dependent variable. Now you plot the data in n-dimensional space with the value of each feature being the value of a particular coordinate( although we don’t know how to plot in more than 3 dimensional space, but mathematically we can conceptually). for this article we will do that in two dimension. Then after we will find a hyperplane that best classify the classes.
And that’s it. Done.
Hyperplane:
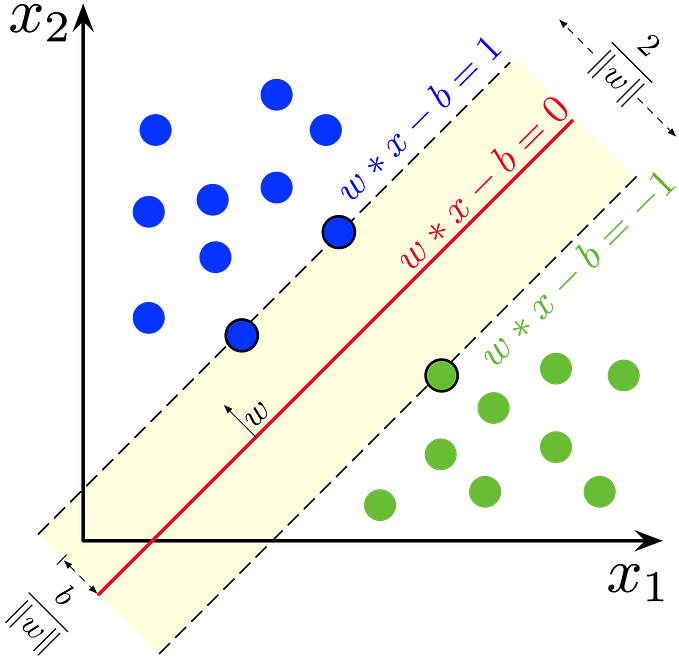
Since there can be multiple decision boundary that can segregate the data, we have to choose the optimal decision boundary. This boundary is called the hyperplane. The dimension of the hyperplane depends on the number of features present in the data. If our data has only two features then it will be a straight line, if we have three features then our hyperplane will be a 2-D plane.
Let’s discuss how to find that best hyperplane(which is in this case is a line).

How to find the best hyperplane:
Look at the image

Case . 1
Here we can see two types of class. And we can see three lines, blue, red and yellow. We can see that red and blue line doesn’t even separate those classes . only yellow line does it. So we choose the hyperplane which segregate the classes better.
Case.2

Here also we can see three lines. Red white and blue. All are separating well, so? Which hyperplane to choose?
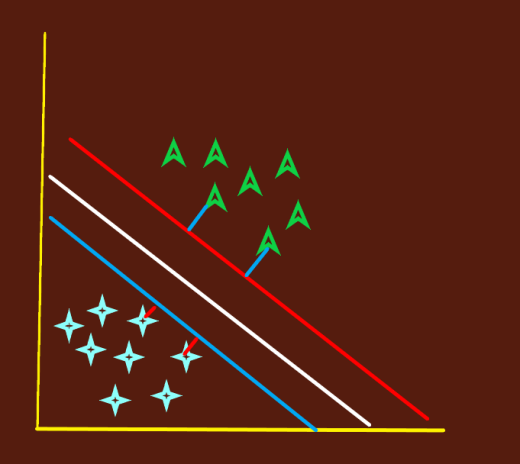
Measure the distance of the nearest data points(either side) from the line, then minimizing the the distance will get us the optimal hyperplane. The distance of the nearest data point from the hyperplane is called the margin. We can clearly see that for the white line the margin for both side is maximum among the lines. So we name the white line as the right hyperplane. Another reason for choosing the hyperplane is robustness. The less the margin for a hyperplane the more the chances of miss classification when predicting on unknown data.
Case 3:
Now look at this
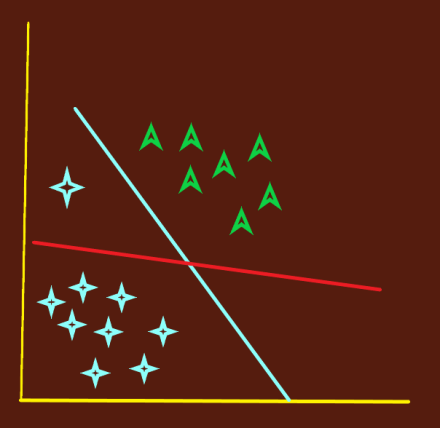
We see two line let’s say the margins for the red line is higher that the blue line. Will that mean we will choose red line as the optimal hyperplane? No. SVM selects the hyper-plane which classifies the classes accurately prior to maximizing margin. Which means classifying the classes better has the priority over the margin.
When in practice we will choose the hyperplanes that classify the data better then we will choose the best hyperplane out of them whose margin is maximum. It’s as simple as that.
Case 4:
Now look at a complex problem. Where we simply can not derive a linear hyperplane .
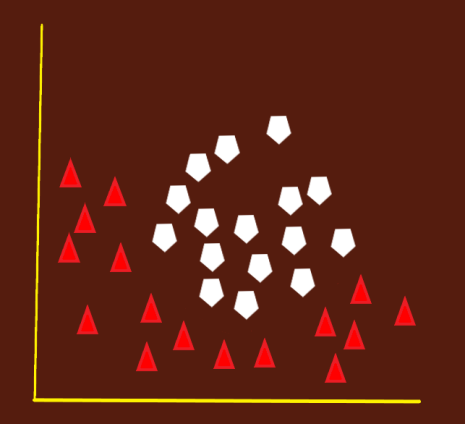
It’s time to introduce kernel trick: SVM solves this problem by introducing an additional feature. Here we will add a new feature z = x²+y²
Which will transform the data into a higher dimension. After transformation this might look like this.
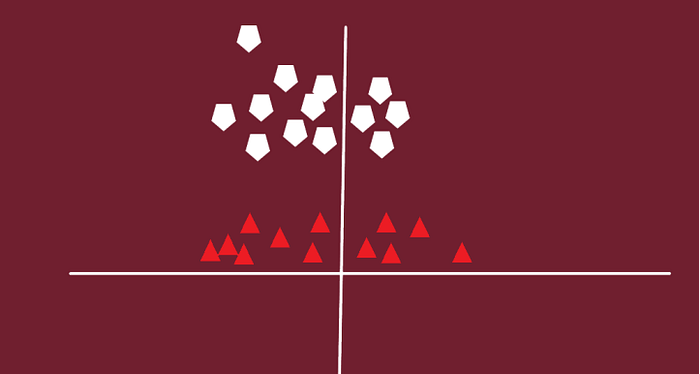
Now the question arises is, should we need to add this feature manually to have a hyper-plane. No, the SVM algorithm has a technique called the kernel trick.
The SVM kernel is a function that takes low dimensional input space and transforms it into higher-dimensional space, I.e. it converts not separable problem to separable problem. It is mostly useful in non-linear separation problems. Simply put, the kernel, it does some extremely complex data transformations then finds out the process to separate the data based on the labels or outputs defined.
So , there are two types of SVM
1. Linear SVM , where the decision boundary can be linear hyperplane. This types of data is termed as separable data.
2. Non-Linear SVM is used for non-linearly separated data, which means if a data set cannot be classified by using a straight line, then such data is termed as non-linear data and classifier used is called as Non-linear SVM classifier.
Anyway you got the idea.
Support vector:
The data points or vectors that are the closest to the hyperplane and which affect the position of the hyperplane are termed as Support Vector. Since these vectors support the hyperplane, hence called a Support vector.
Equation of hyperplane :
It can be easily written as
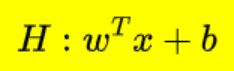
In two feature it’s
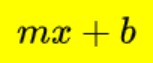
Where m is the slope and b is the intercept.
In D dimensional plane w would always be of D-1 dimensional.
Distance Measure :
To find the best hyperplane that segregates the data point we have to measure the distance from the support vector to the hyperplane (which is called margin).
The distance of a plane whose equation is

From a point (a_1, a_2, …, a_n) is d given by
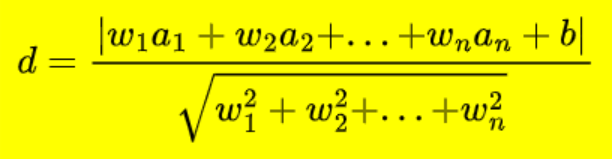
remember: Our goal is to maximize the minimum distance.
with that being said we reached the end of this article. If you think that there are some issues that need to be fixed please let me know in the comments.
want to connect?