Linear Regression, A Quick, short but efficient note

What is Linear Regression?
It’s well known supervised machine learning algorithm. It can perform a regression task. I.e. it is used for finding relationship between independent variables and target variable and predictions.
It basically predicts the value of a dependent variable(we’ll call it ‘y’) based on a given set of independent variables (x). what it does is it finds out a linear relationship between x and y. I’m repeating ‘a linear relationship’. hence the name linear Regression.
Model representation
It’s a simple linear equation with x and y. that is a specific set of input values or independent variables and the predicted output upon x or our target variable.
It’s kinda looks like

or in matrix form

Where is the coefficient of x and B0 is bias coefficient or intercept. Here B1 and B0 are unknown, we have to find them . (we are writing B1 and B0 instead of Beta_1 and Beta_0)
We can consider x as a 1×m matrix, where m is the number of independent variables and B1 as a m×1 matrix.
Our goal:
is to obtain a line that fits the data best. The best fit line is the one for which total prediction error is as small as possible. How we find the error is a matter of discussion we will do later in this post. And one more thing, line here doesn’t always mean actual two dimensional line. It can be a plane or hyperplane in more than three dimensions.

Our task:
it’s actually simple but not so easy. We just have to find the coefficients B1 and B0. Once we find the values for B1 and B0, we get the best fit line. Then we can use the model for predicting the values of target variables on unknown data.
How to find values of B1 and B0:
for that we have to know another concept , ‘Optimization’. but before going into that , let us discuss about error or cost function.
Cost function :
the formula is

That is the Root mean squared error (RMSE ) between predicted value y_pred and true value y.
But we didn’t have the the y_pred value yet. Yes, but if we use any random values for B1 and B0 that will obtain a predicted value for y. we will update and improve this value by optimization.
Optimization (Gradient Descent):
The formula for Gradient descent is

We use this to update the values of B1 and B0 in an iterative process to reduce the value of cost function and eventually achieving the the best fit line.
Since B1 is a m×1 matrix it has m components, say

Gradient Descent works by starting with random values for each coefficient. The sum of the squared errors are calculated for each pair of input(x) and output (y) values. A learning rate(α) is used as a scale factor and the coefficients are updated in the direction towards minimizing the error. The process is repeated until a minimum sum squared error is achieved or no further improvement is possible.
When using Gradient descent we must have to choose a learning rate (α) parameter that determines the size of the improvement step to take on each iteration of the procedure.
We have to select learning rate suitably, If we take alpha too small it will take much time to reach the convergence and if we take bigger learning rate then it might not converge at all and will continue fluctuate all around.
The partial derivative is as stated , with respect to the specific coefficient we are trying to improve.
Regularization:
this method try to both minimize the sum of the squared error of the model on the training data (using ordinary least squares) but also to reduce the complexity of the model.
There are two most popular examples of regularization.
1. Lasso regression(L1)
2. Ridge regression(L2)
Prediction :
as now we have the best fit line that means the coefficient, and knowing that the representation is a linear equation , prediction is an easy task.
Our eq is
Now let’s say we have to predict y for some x. we just have to calculate some simple multiplication and addition to get the value of y.
Simple Linear Regression and multiple linear regression:
If we have a single independent variable x, I.e. the matrix x is 1×1 , so our coefficient matrix B1 will also be 1×1, then it is called simple linear regression.
If we have more than one independent variable , I.e. the matrix x looks line
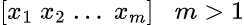
Then it is called multiple linear regression.
Important Notes:
1. LR assumes that the relationship between your input and output variable is linear. It might seem obvious in this context but it’s important to remember. If your data has not a linear relation in between this will not work. you might have to transform the data to make the relation linear.
2. LR assumes that your data is noise free. If your data has noise that might Affect the coefficient. Consider data cleaning before applying the model. Like removing the outliers, etc.
3. If you data have high co linearity between input variables, it will over-fit, a worthy problem we will discuss on later posts. Consider removing input features with high collinearity.
