Hyperparameter tuning guide

introduction
in machine learning hyperparameter optimization or hyperparameter tuning is one of the most Important part that everyone should consider. It affects your model heavily. In this article we are gonna discuss three important questions. They are..
A. What are hyper parameters?
B. What is hyper parameter tuning (optimization)?
C. How to optimize hyper parameters?
Okay so let’s jump in ..
A. What are hyperparameters in the first place?
Hyperparameters are the parameters that cannot be estimated by the model itself and you need you specify them manually. These parameters affects you model in many ways for a specific set of data. For you model to perform best you have choose the best set of hyperparameters. Examples are max depth in Decision Tree and learning rate in deep neural network. These hyperparameters have a direct effect on whether your model will be Underfitting or overfitting. The Bias Variance trade-off is heavily rely on hyperparameter tuning. So to get the optimal hyperparameters are our goal. Remember that for different data set our optimal hyperparameters will change.
There are other parameters named model parameters present in the model. But the good news is we don’t have to optimize them manually. The model itself can do that. The model estimates those parameters from the data. Examples are the weights in Neural Network. Optimization algorithms like Gradient Descent, Adam etc. are used for this kind for parameters.
B. What is hyperparameter optimization or hyper parameter tuning?
In most of the ML models you’ll have multiple hyperparameters. Choosing the best combination requires an understanding of the models parameters and the business problem you’re trying to tackle. So before doing anything you have to know the hyperparameters of the models and their importance.
To get the best hyperparameter the two step procedure is followed .
1. For each combination of hyperparameters the model is evaluated
2. The combination that gives the best performing model are selected as optimal hyperparameters.
So , put simply, choosing the best set of hyperparameters that result in the best model is called hyperparameter tuning .
C. How to optimize hyperparameters?
There are two ways to find the best hyperparameter setting .
A. Manual search
B. Automated search
Let’s look at these method more closely
A. Manual search.
You might have guessed it right. Yes manual means manual. I.e. you experiment with every combination of hyperparameter sets and choose the best one. This is hard and require experiment tracker. If you’re researching on tuning then it’s good as it gives you control over the process. But remember this is not practical method for hyperparameter search. With the huge amount of trials it is very expensive and time-consuming. So just leave it, we are not gonna talk about this.
B. Automated search
This works as
1. You specify a set of hyperparameters and limits to their values. A dictionary is used do this task.
2. The automated algorithm is there to help you with. It runs the trials or experiments that you would do in manual search yourself and returns the best set of hyperparameters that gives the optimal model.
And it’s done.
There are numerous hyperparameter parameter optimization method are there. But in this article ae will use two of the most popular optimization method
1. Grid search
2. Random search
Let’s get to this one by one..
1. Grid search
Let’s we have two hyperparameter ‘gamma’ and ‘kernel’. and their values are
‘gamma’ : [1, 0.1, 0.01,0.001]
‘kernel’ : [‘rbf’, ‘linear’, ‘sigmoid’]
Now the algorithm makes a grid of these two arguments in a 2D plane like this
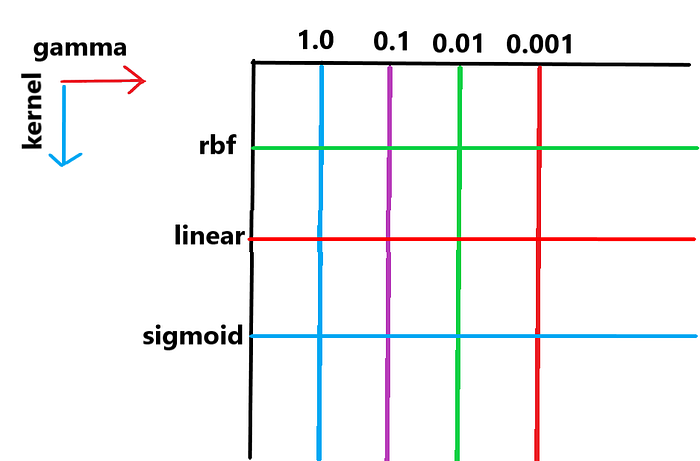
We can see the grid formed here. Now what the algorithm does is for each of the inter section point it runs the model with the hyperparameter combination It have. Like in in first iteration the hyperparameter set will be [‘rbf’, 1.0] then in the next iteration [‘rbf’, 0.1] etc.
After running all of the grid points it will choose the best performing model and return it. Remember the name Grid search CV , the CV stands for Cross Validation. For each iteration it performs the cross validation techniques the get the best model with the hyperparameter setting for that iteration. We already have published a article on Cross Validation. So please check out this article for better understanding of Cross Validation.
Now to implement Grid search CV in python is quite simple. Briefly speaking you make a python dictionary of all the hyperparameter you want to consider. Use Scikit Learn library to use the method GridSearchCV( ) and put in the model instance, parameter grid (the dictionary you just built), evaluation metric, number of cross validation. We are not going into the python implementation of Grid Search CV in this article. There are many such article present. I am linking some of them here. They are very good for understanding the process.
2. Randomized Search CV
As the name suggests we take the hyperparameter combination at random. That means unlike Grid Search where we used every possible hyperparameter combination here we sample values from a statistical distribution for each hyperparameter. A sampling distribution is defined for every hyperparameter to do a random search.
In this way you can control the number of attempted hyperparameter combination. That means when you four hyperparemeter and each have 4 distinct values to choose from Grid search CV will train the model 4 ✖ 4 ✖ 4 ✖ 4 = 256 times. We may not have that much of computing resources in some cases and times too. In Random Search we can specify the number of iteration through the n_iter argument in the Sklearn library method RandomizedSearchCV( ) method. Let’s say you choose n_iter = 100. though you have 264 combination possible this algorithm will conduct only 100 Randomly selected combination. After all the specified combination are finished the best one will be returned. And you got the best model. For python implementation of Randomized Search CV please refer to this page.
Note:
When we have a small amount of data and smaller number of hyperparameters Grid search is a preferred choice for hyperparameter tuning. As it tests every combination possible and guarantees accuracy. But when you have large amount of data it doesn’t seem feasible. With greater dimensionality greater number of hyperparameter combination to search and train the model. This would take so much time. The computer resources in use is also a problem.
Randomized search let’s you take control over the number of iteration to be computed. Although it may not be as accurate as the previous one but with increased number of hyperparameter values and data size Randomized search is definitely a better approach.
With that being said we will wrap up this article here. Please correct us where we are wrong or where we could be more specific or things like that. The comment section is for you to have a say.
If you like this post please follow me on medium
Or these alternatives
Thank you all
Reference :
https://neptune.ai/blog/hyperparameter-tuning-in-python-complete-guide
