Decision Tree concepts simplified

as in other articles I am not going explain the whole algorithm, but in this post I am going to discuss some of most important concepts that are needed to master an machine learning algorithm which is decision tree algorithm. I assure you that after this article you would be very much ready to encounter any blog, video or books about decision tree. So without any further delay let’s look at the most important concepts of the algorithm.
Entropy:
But before I say anything let’s look at this data. It will be our reference in every block.

This is a data about farming. The features are soil condition, how much grass are there and how the weather is. Based on these condition we ant to know whether we should plant the seeds or not. Okay let’s begin.
I am assuming you know what a node or root or leaf node is.
Entropy is the measure of randomness or impurity of a node. It tells us how random is our data. The more variation in our data the more the entropy. For our decision tree a bigger entropy is bad and a lower entropy is good. A branch with entropy 0 is a leaf node and a branch with entropy greater than 0 needs further splitting. Mathematically entropy for 1 attribute is given by

Let’s see for planting


Which is the greatest that can ever be
For probability 1 or 0 the entropy will be 0 and for probability 0.5 Entropy will be 1(highest).
Mathematically entropy for multiple attribute is given by


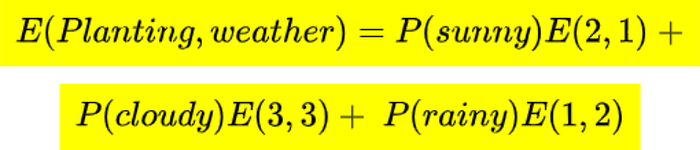
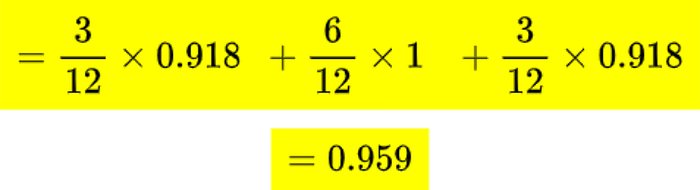
Remember we use a weighted average to calculate the entropy.
Now that entropy is covered we can go into Information gain.
Information gain(IG):
When building a decision tree it’s a tough call to choose the first attribute to go with as root node. We use Information gain for this. Information gain measure the reduction in uncertainty. You can imagine it as a measurement of how well an attribu8te separates training examples according to their target classification.
When building a decision tree we will IG a lot.
Mathematically Information gain is decrease in entropy. It computes entropy before split and after split for a given attribute.
In our dataset we have three attributes. We will use IG to see which attribute to choose as a root node.
Mathematically
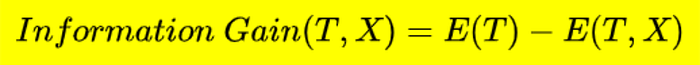
Let’s check for all our attributes

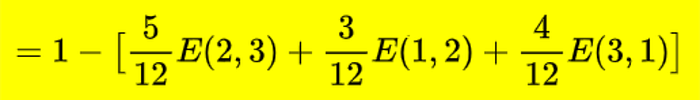

Which is not so great.
Similarly we calculate

And

We can see that the soil cond feature has the highest information gain. Hence we will select the feature soil cond and split the node based on this feature.
We will do the same for the sub nodes. The more the information gain the better it is for splitting.
Note: Information gain is non negative.
Gini Index:
Mathematically
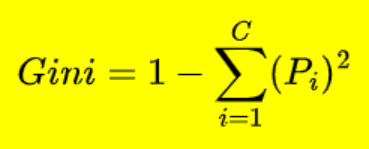
It is calculated by subtracting the sum of the squared probabilities of each classes. Gini index works with only binary categorical variables. higher value of Gini Index implies higher impurity. Higher heterogeneity.
Homogeneous means having similar behavior with the class. If nodes are entirely pure then it will have responses of one class. Heterogeneous is opposite of that.
Similarly that we have calculated Information Gain for each features and choose the highest of them to select the root node, now we will use Gini Impurity to choose the node.
Step 1. calculate the p² + q² for yes(p) and no(q) using the above formula.
Step 2. Calculate the Gini index for split using the weighted Gini score of each node of that split.
For our data set let’s choose soil cond feature first and calculate Gini index.
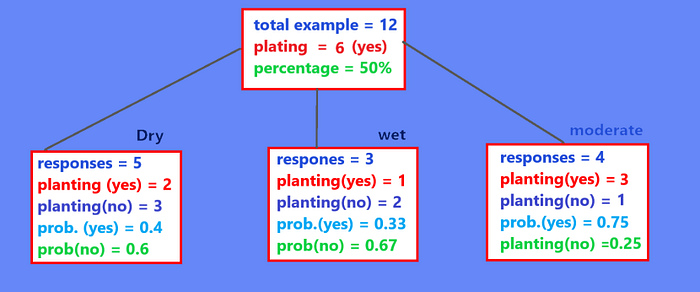
Now let’s calculate Gini impurity for sub nodes
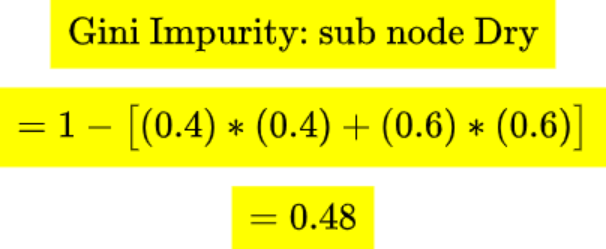
So it comes out as 0.48
No we will calculate this for wet and moderate soil cond too.

And

we will take the weighted Gini impurities of all the nodes. the weight of a node is the number of samples in that node divided by the total number of samples in the parent node.

Similarly we calculated weighted Gini impurity for other features. They turns out to be

and
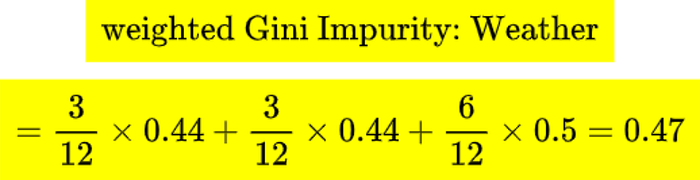
No let’s compare those weighted Gini Impurity
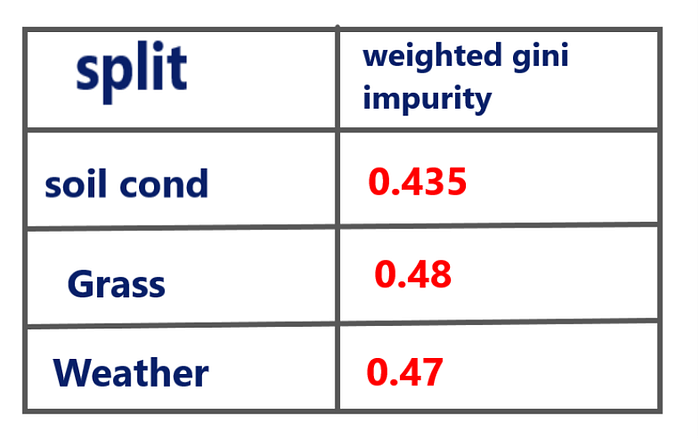
We see that the Gini impurity for the split on Soil cond is less. And hence Soil cond will be the first split of this decision tree.
minimum value on Gini index will mean the node will be more homogeneous. So for further splitting we can use Gini Impurity.
There are more things to discuss in this blog , but as this article is getting more complex and lengthier we will end this article right here. On part 2 we will discuss about gain ratio , different Decision Tree algorithms and how they works and many more.
Please follow me on medium or any other social link mentioned below and be sure to comment your thoughts whatever it be in the comment section.
With that being said. Thank you, bye.
